Spark Structured streaming is a new way of handling live data and built on SQL engine that supports both Dataframes API to run SQL-Like queries and DataSet API to execute scala operations on your datasets. It provides fault tolerance and scalability. Structured Streaming based on continuous processing in which data received is appended and processed continuously, thus providing more real-time streaming. However, how fast results write to storage/sink depends on the output mode, which is configurable.
Spark Streaming versus Structured Streaming
Prior to Structured Streaming, there was Spark streaming in the Spark framework that was used to process stream data. Spark Streaming has many loopholes that were addressed by Structured Streaming in Spark 2.0 version. Below are a few of the differences between both.
Real Time
Structured Streaming is more inclined towards real-time processing, as there are no concepts of micro-batches. As soon as data is received, it is added to the unbounded table whereas, in Spark Streaming, data collected till batch duration, and then is divided as RDD to further processing.
Performance
Spark Streaming based on Dreams API, which internally uses RDD whereas Structured Streaming uses, Data Frames/Datasets API for computation. Dataframes/Datasets APIs are more optimized and faster as compared to RDD’s, thus Structured Streaming is faster than Spark Streaming because of underlying APIs.
Handling Late Elements
In Spark Streaming, there was no provision to process the data based on the event-time, which is the actual timestamp when data is generated in the physical world thus handling late elements was a bit difficult in case of Spark Streaming whereas with the advent of Structured Streaming handling data based on the event time has become possible.
How Structured Streaming works?
Structured Streaming has changed the way Spark used to deal with real-time data. Earlier data was collected at the batch interval and then divided into micro-batches for further processing, which makes it near real-time processing. However, Structured Streaming can be called as real-time processing as it can process the streaming data at a latency of 1 ms.
In structured streaming, data regularly polled at certain defined intervals, and new data paired to the unbound table, and then the calculation is applied to whole data or only new data depending on the operation mode. Finally, the computed output write to Result Table.
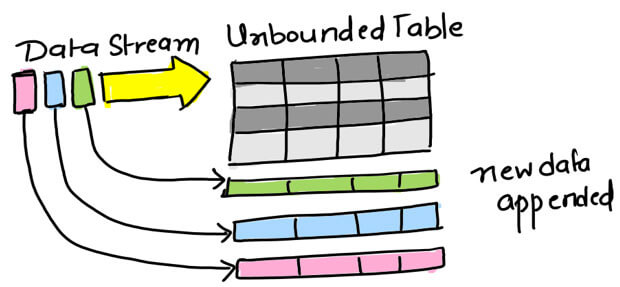
Output Modes
Output mode will decide how result data would write to storage. There is three output mode at which result data write to storage.
Complete Mode: In Complete mode, all of the resulting data in the table written down, whether it is old data, new data, or updated data.
Append Mode: In Append Mode, only new data written to result in a table.
Update Mode: In update mode, write only rows that have updated.
Getting Started with Structured Streaming
Creating Spark Context
The first step to getting started with a structured streaming code is to create a spark session object.
Reading Data
Once you have created your spark session object, you can create Dstream from any incoming streaming using the readStream method on spark sessions and providing valid options. Suppose my input data consist of google location data that is coming continuously as JSON stream from Amazon s3. Below the sample code demonstrates how you can create Dstream, from the JSON stream.
Transforming Data
After creating your Dstream, you can apply any type of transformations or SQL query on top of your data to get some desired result. For example, you can group your data based on the country.
Writing Data
Once you apply, all transformations on your input data to get the desired output. Now is the time to write it back to some storage device, database, and another streaming engine or Kafka topic. For example, let’s write our results to the Mysql database.
Running SQL Queries
Structured Streaming has also made possible to run SQL queries on top of streaming data. You can register your dataframe as a temporary view on top of which you can run SQL queries. Let’s read the same Json stream that is coming from Amazon S3, and that consists of location details (name, latitude/Longitude and country name), and then apply the SQL query to count the number of each country by grouping the data with country name.
Windows Operation
Windowing is the core concept of streaming pipelines since it is mandatory to analyze the incoming data within specified timelines. Structured Streaming provides us with the flexibility to apply window on aggregation function as well. For example, in the below code, you can specify that you want to group data in the 1-hour window. Structured streaming also handles late data based on data event time.
Reading & Writing from Kafka
Structured Streaming provides inbuilt API to integrate with the most popular messaging framework that is used in the market today that is Apache Kafka. Apache Kafka can act as a source as well as a sink for streaming data. You can read the data from Kafka topics and can write your results back to Kafka topics. The below code represents how we can read data from the Kafka topic and write the result back to the Kafka topic. It is also possible to read from multiple Kafka topics and to read messages based on some patterns from the Kafka topic.
Reading from Kafka Topic
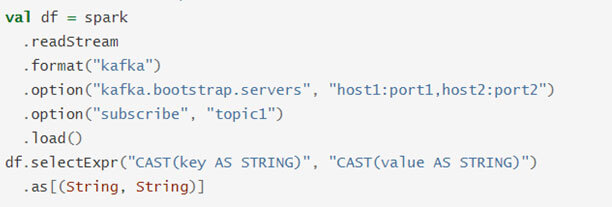
Writing to Kafka Topic

Conclusion
Structured Streaming is much more promising and efficient in the streaming world as compared to Spark Streaming. It is still not a real-time processing engine, but it is moving a step closer to it. Apache Flink and Google dataflow are its major competitors, but Apache spark services has its place in the market. It is still evolving at a fast pace to provide more integrations with other systems.
For further information, mail us at info@aegissoftwares.com