
Understanding the Importance of ELK Stack in Java Microservices
- In this blog, I have explained what a Spring data elastic search and with an example. ELK stacks stand for Elasticsearch- Logstash-Kibana. When running micro services along with the ELK stack, the above architecture is generally followed. There will be multiple micro services running and they will generate logs. So, these logs will be read by the Logstash and they are indexed to the central Elastic search server. And from there, Kibana is used that provides UI by taking the data from Elastic search results.
- Actually, the ELK stack consists of Elastic Search, Logstash, and All these products are provided by Elastic itself. Theoretically, Elastic Search is nothing, but a NoSQL DB created out of Apache Lucene. It will be the central repository where the data/logs will get stored.
- Suppose you have multiple spring boot applications or micro services and these applications produce enormous logs which is very difficult to handle these logs and analyze from these log files are the files will be many. Here in this scenario, you can use the ELK stack more efficiently provide by Java application development company.
- Suppose you have your application in the Prod Environment and let’s say the client is making the request from the browser to your server where your application is running. So, in that application, there can be some errors or warnings,s or success logs. So, all these data are being written to the Log file by using SLF Log 4j. These log files may contain many numbers lines and searching some text or error message from that log file is not easy to process.
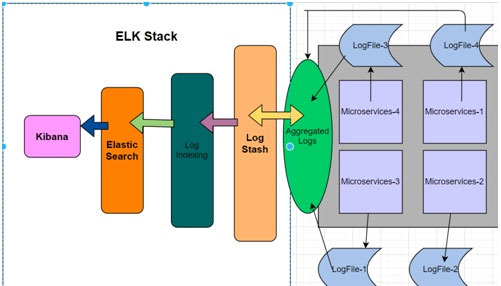
Use case of ELK stack in Java micro services Applications
- We want to see the logs in a User Interface(UI), so that developers or support persons can search the logs easily. This UI is from Kibana only as I mentioned earlier. But in our case directly the logs won’t be sent to Kibana. We need intermediate software to be in place that is Elasticsearch and Logstash.
- So, we have to use Logstash to read log files of various applications. If you provide the Log file location, then Logstash can read the log file from that path. Once you read the logs the next step is to filter the logs. Whenever any exception message is printed, then there are some stack traces that will get printed in multiple lines.
- And we don’t need the entire lines of exceptions, in this case, only the specific exception mainline and error message we want. So, here we have to do some filtering or customization in reading the log files.
- In this case, we will be using one analytical tool called Elasticsearch which will search our logs and analyses and filter according to our custom logic. Then it will feed those filtered logs to Kibana. Elasticsearch is a search tool and it supports data filtration. Internally it is going to work on JSON-based.
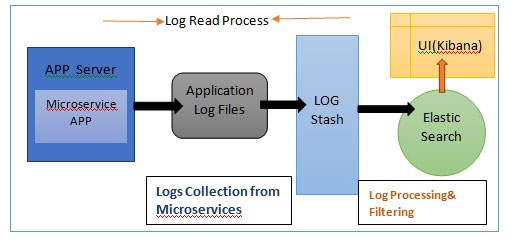
But here in my example I have not discussed the entire ELK stack but only explained the implementation of Elastic Search with Springboot.
- You can create through the initializer with the“https://start.spring.io” and create the application from there. We have to includes the dependencies for Web as the web is going to expose our spring code application via the rest endpoint and also we need Elasticsearch dependency which gives us the elastic search dependencies which we need for building a spring data elastic search module.
- So, if you are not aware of elastic search then just giving a theoretical explanation of elastic search i.e. a search engine that is built out of Apache Lucene that stores the data in the form of JSON messages or JSON format. You can easily query and search for the data using the HTTP calls. So, spring data is going to have a wrapper around this elastic search and then it makes our life simple in terms of querying and loading the data from elastic search.
Elasticsearch Implementation with Springboot
- Let’s create a dummy project with the required elasticsearch dependency. We need to have a loader so what we are going to do is we are going to load the data into the elastic search. We also need some config files it's not a config file and these are some configurations that we need while loading the elastic search. Then we require the repositories which are similar to the JPA repositories but here we will create a elasticsearch repository. Finally, we need a controller for exposing the rest endpoints.
- For elasticsearch configuration, first, annotate the class with @Configuration and then to annotate it with elastic enables elastic repositories, use @EnableElasticsearchRepositories. So, once you enable elastic repositories, you have to add the base packages with mentioning your path of elastic repository class. You need to give the package structure for the repository so that when the Springboot comes up it automatically scans the repository and identifies that it's an elastic such repository.
- The above lines are going to scan through the files and the repository folder and create a repository for the elastic search. Once that is done, you need to create a bean for Node builder where node builder is provided by elasticsearch which is in turn provided by Storing Data.
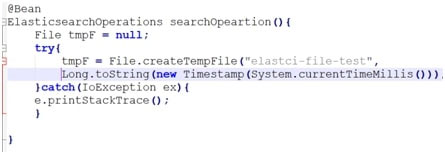
- The next one would be to create a bean of Elasticsearch operation. What we are going to do here is to create a temporary file in a specified location in the local directory. And also, we can give some timestamps so that a folder structure has a unique name.
- These are the things that are required for elasticsearch to kick-start. What happens here is it is going to create an elastic with the default configuration and the blow settings are used in the XML previously but now in my example, I have moved all the settings to the way of Springboot standards.
- Here, I have mentioned what is the path for the directory where elastic should be stored. The elastic search is going to be saved in the local repository so it's not going to have an in-memory database or something it's going to store everything inside the files. That is the path on which we have created the temp File.



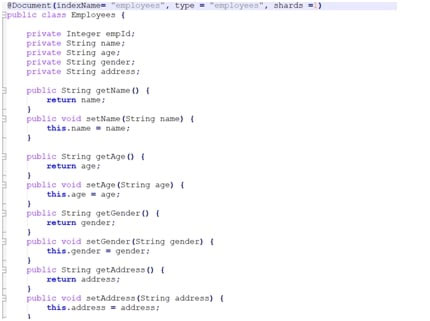
Creating Repository and Document Model for Elastic Search
- Now, Let’s go to the repository and create a repository class. In our Repository interface, it has to extend the ElasticsearchRepository class from the Spring data package. Then we have to add the entity called Employees and for creating a model, you have to use the annotation called @Document which is specific to the elastic search. Here inside the document model, we have to give all the index names so for example here let's say we want the index name as “Employee” and we need to mention the type as well.
- Then you have to mention the shards. I have mentioned there was only one shard initially when I created the configuration for Elasticsearch, I created the setting with 1 shared partition. Then we have to mention all the fields which we need to use as part of the Employees Model and create a constructor for initialization and then create getter and setters method as mentioned below screenshot:
Model Class:
- let's go to and create a Loaders class and we have to annotate it with @Component and inside the Loaders class, I have declared@PostConstruct annotation where this post constructor will be executed whenever this particular post construct method will be executed whenever Springboot will start the Loaders class. What I am going to inject is the repository which we created the Employeerepository which is plugged into the elasticsearch and also we are going to insert a new object which is called elastic search operations where we will be putting all the mappings.
- Before we process the data into the elastic search, we need to create a mapping with the putMapping() method from the ElasticsearchOperationsWe can add mappings for the Employees model where this particular model mapping needs to be created. The ElasticsearchOperations has put mapping that creates a mapping for these Employees. Now I will use the repository class to load the data. In the example, I have given some temporary data.
Data gets Loaded to Elasticsearch through This class
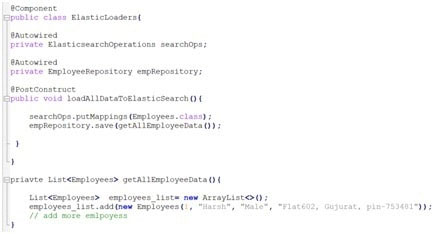
- So, once the mapping is created it's going to load the data into the repository and the repository is nothing but the elastic search repository. Don’t confuse it with JPA repository class.
- So this is going to load the data into the elastic search okay and till now you know that the data have been loaded when the spring boot application starts because we have annotated this particular class with components because that instance of this class will be created when the application boots up and also as we have added a @PostConstruct annotation, when class is getting loaded then it will execute this particular method.
- We can also add a transactional annotation so that this particular method will be executed as a transaction and if something fails it can't hold back so that is just the @Transactional annotation.
Creating the Rest Endpoint
- Here, I have added the resources so that we can find the data using the get endpoint. Once you hit the rest endpoint, this is going to find the data from the elastic search and inside the method, it is literally going to search the data. How do we search? How to find out the nearest Parking Spot availability in Java?
- Here, we have to inject the Employee repository which we had created above by which we loaded the data. Using the same repository, we can get the data. Now we need to write a rest endpoint with GetMapping and here as I am going to search by name, I have given the endpoint name as “/name/{resource}”.It will be getting a list of users for that particular name.
- I have used the EmployeRepository to do a find by name using findByName() If you are aware of the spring JPA, by using this method you can search by a particular field, and this gets translated into literary like a select query. So, Spring boot is following the same way inside the elastic search.
- This particular method doesn't exist, but we can create that into the interface which we have done earlier. So, what happens is on the fly this gets converted into a query which elastic search can understand and search by the field called “name” under the EmployeesEntity.
- In this method, we are going to search by the name as below:

- We can add a few if we want to play around with this elasticsearch methods. We can create different rest endpoints if you want to search all the data from the elastic search. We have to use one iterator for iterating all data and then mapping it to the Employee Model as below:
- Instead of the Spring data, Elastic gives us some default way of querying with find by name or findByAge() just similar to JPA queries, you can also try something advanced with the Elasticsearch.
- In the above code snippet you can see the ManualQueryController class where I have autowire the SeachQueryBuilder class and then calling the getAllEmployeeData() method where I am manually building a query to fetch only EmpId and Employee Name but not the other fields. Spring data Elasticsearch provides us this NativeSearchQuery class through which we can be able to execute our customized query.
- Elastic search provides us ways where you can create your manual queries with the help of QueryBuilder and finally, you can execute your customized query with the help of ElasticsearchTemplate class



FAQs:
Subject: Implementing Elasticsearch with Springboot in ELK stack-based Microservices
What ELK stack and where it is used?
Ans: It is anELK stacks stand for Elasticsearch- Logstash-Kibana. When running micro services along with the ELK stack, the microservice architecture is generally followed. There will be multiple micro services running and they will generate logs. So, these logs will be read by the Logstash and they are indexed to the central Elastic search server. And from there, Kibana is used that provides UI by taking the data from Elastic search results.
Why Elastic search is used frequently in many Java-based micro services Applications?
Ans: Elastic search i.e. a search engine is built out of Apache Lucene that stores the data in the form of JSON messages or JSON format. You can easily query and search for the data using the HTTP calls
How to implement Elasticsearch with Springboot 2.0?
Ans: For this, we need Elasticsearch dependency which gives us the elasticsearch dependencies which we need for building a spring data elastic search module. Then for the detailed implementation details, please read this blog thoroughly.
How you can create a Document Model for Elastic Search Implementation in Springboot?
Ans: You have to create a repository class. In our Repository interface, it has to extend the ElasticsearchRepository class from the Spring data package. Then add the entity for example called Employees model and for creating a model, you have to use the annotation called @Document which is specific to the elastic search.
Create a rest Endpoint for Searching specific logs from the Microservice Application logs files?
Ans: This is an end-to-end implementation project using Springboot Data Elasticsearch. I have explained in this blog by creating a sample rest API where I am filtering log data produced from different Microservice Applications